PSML Schematron
Schematron enables developers to implement multiple validation regimes for any document set. For further information, see the article on Validating documents or the Schematron website .
When editing schematron files in PageSeeder, pressing ctrl-space displays autocomplete options to make editing easier.
View schema
To view Schematron schemas, in the Templates configuration administration page, select the Schematron column and the row for the particular document type or media type.
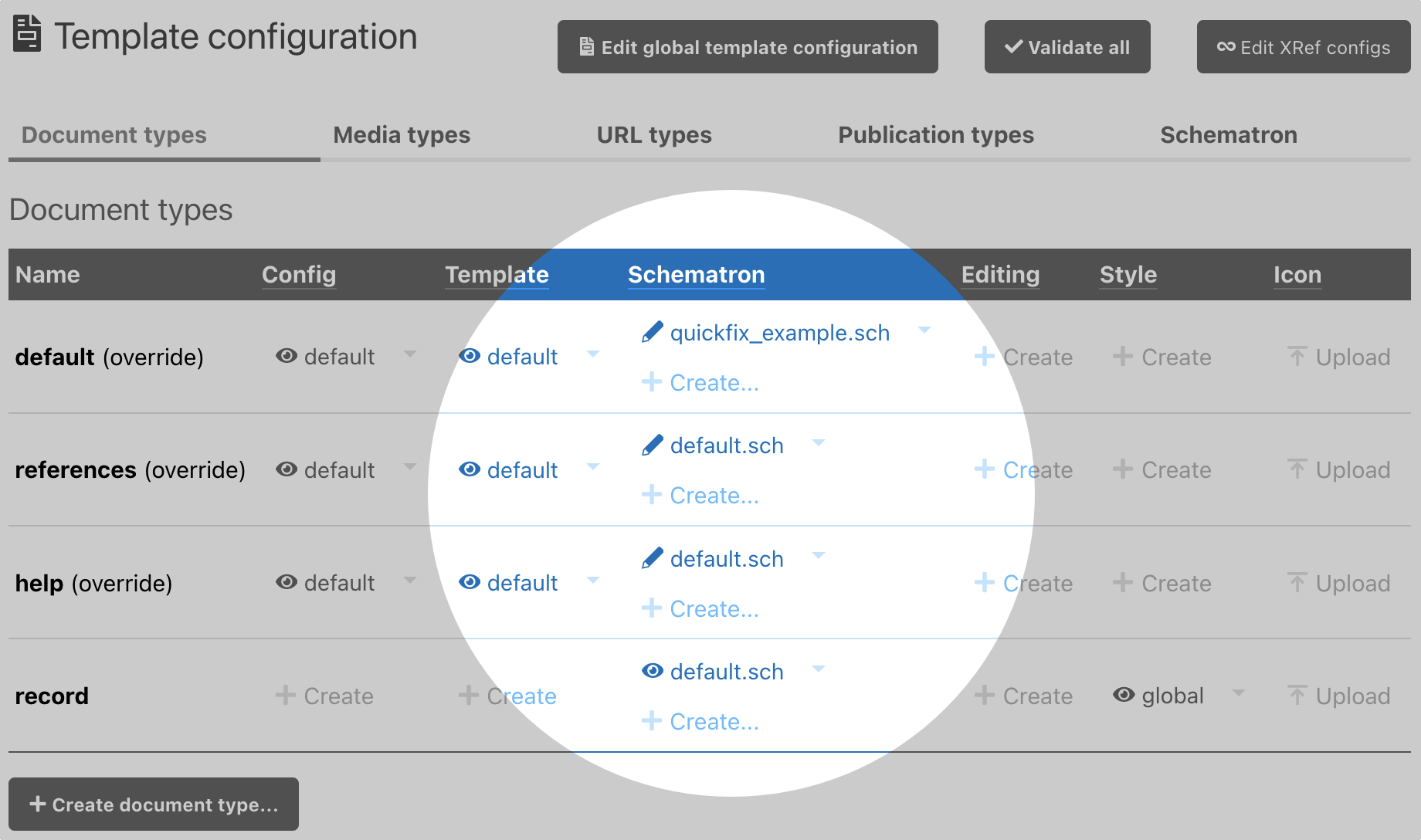
Example schema
The best_practice.sch schematron file is used to validate and report on PSML documents.
<!--
This schematron defines the general best practice recommendations
by PageSeeder for general purpose PSML documents (which do not use
complex templates).
The schematron rules defined here are meant to provide guidance
for users on how to produce quality PSML documents.
@version 5.7902
-->
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron">
<sch:title>Best practice</sch:title>
<!--
Set of rules applying to the entire document
-->
<sch:pattern name="Document">
<sch:rule context="/document">
<!-- The document title should match the first heading -->
<sch:assert
id="MISMATCHING_TITLE"
test="documentinfo/uri/displaytitle = (//heading)[1]">
The title of this document
'<sch:value-of select="documentinfo/uri/displaytitle"/>'
does not match the first heading of the content
'<sch:value-of select="(//heading)[1]"/>'.
</sch:assert>
<!-- The document should not have more than one heading 1 -->
<sch:assert id="MULTIPLE_HEADING1"
test="count(//heading[@level=1]) le 1">
Your document should not have more than one heading 1.
</sch:assert>
<!-- Documents should not have more than 20 sections -->
<sch:assert id="TOO_MANY_SECTIONS"
test="count(section) le 20">
Your document contains over 20 sections.
Having too many sections in a document make it difficult
to read and edit and may lead to performance issues.
You should consider splitting your document into multiple
documents.
</sch:assert>
<!-- Document IDs can improve documents -->
<sch:report id="NO_DOCUMENTID"
test="not(documentinfo/uri/@docid)"
flag="tip">
Your document does not have a Doc ID.
Specifying a Doc ID makes it easier to identify and find
your document in PageSeeder.
</sch:report>
<!-- Labels can improve documents -->
<sch:report id="NO_LABELS"
test="not(documentinfo/uri/labels)"
flag="tip">
Your document has no label.
Attaching labels to a document makes it easier to
categorise and find your document in PageSeeder.
</sch:report>
<!-- It may be useful to check the number of words in
a document -->
<sch:report id="WORD_COUNT"
test="section"
flag="info">Document contains
'<sch:value-of select="count(tokenize(normalize-space(string-join
(section//text(), ' ')), ' '))"/>' words.
</sch:report>
</sch:rule>
</sch:pattern>
<!--
Set of rules applying to the document fragments
-->
<sch:pattern name="Fragments">
<!-- Rule matching regular fragments -->
<sch:rule context="fragment">
<!-- Fragments should start with a heading id="NO_HEADING" -->
<sch:report id="NO_HEADING_START"
test="not(name(*[1]) = 'heading')"
flag="tip"
diagnostics="fragment">
Fragment '<sch:value-of select="@id"/>' has no heading.
It is better practice to start each fragment with a
heading.
</sch:report>
<!-- Fragments should avoid including multiple headings -->
<sch:report id="MULTIPLE_HEADINGS"
test="count(heading) gt 1"
flag="info"
diagnostics="fragment">
Fragment '<sch:value-of select="@id"/>' has
multiple headings!
</sch:report>
<!-- Fragments should not be too long (over 2000 chars) -->
<sch:assert
id="LONG_FRAGMENT"
test="string-length(string-join(.//text(), '')) le 2000"
flag="tip"
diagnostics="fragment">
Fragment '<sch:value-of select="@id"/>' has
<sch:value-of select="string-length(string-join(.//text(), ''))"/>
characters (more than 2000).
You should consider splitting this fragment.
</sch:assert>
<!-- Large fragments display change tracking (over 2000
elements/attributes/text nodes)
-->
<sch:assert id="COMPLEX_FRAGMENT"
test="count(.//*) * 2 + count(.//@*) +
count(.//text()[normalize-space(.)!='']) le 2000"
flag="tip"
diagnostics="fragment">
Fragment '<sch:value-of select="@id"/>' has
<sch:value-of select="count(.//*) * 2 + count(.//@*) +
count(.//text()[normalize-space(.)!=''])"/>
elements/attributes/text nodes (more than 2000).
You should consider splitting this fragment to enable
change tracking.
</sch:assert>
<!-- "code" style on multiple lines should use "pre" style
instead
-->
<sch:assert id="CODE_MULTIPLE"
test="not(para[monospace[. = ..]]
[following-sibling::*[1][self::para][monospace[. = ..]]])"
flag="tip"
diagnostics="fragment">
Fragment '<sch:value-of select="@id"/>' has two
consecutive paragraphs containing only "code" content,
consider using the "pre" style.
</sch:assert>
</sch:rule>
<!-- Rule matching table rows -->
<sch:rule context="row">
<!-- Table header rows should only be at the top of
the table
-->
<sch:assert id="MISPLACED_TABLE_HEADER_ROW"
test="not(*[position()=last() and self::hcell]
and preceding-sibling::row/*[position()=last() and self::cell])"
flag="warning"
diagnostics="fragment">
Fragment '<sch:value-of select="ancestor::fragment/@id"/>'
has a table header row not at the top of the table
starting with content '<sch:value-of select="*[1]"/>'
</sch:assert>
</sch:rule>
<!-- Rule matching blockxref -->
<sch:rule context="blockxref">
<!-- Embedded single fragments should not be used -->
<sch:assert id="EMBED_SINGLE_FRAGMENT"
test="not(@type='embed' and @frag!='default')"
diagnostics="fragment">Fragment
'<sch:value-of select="ancestor::fragment/@id|ancestor::xref-
fragment/@id"/>'
has a cross-reference
"<sch:value-of select="."/>" embedding a single fragment.
Replace this with a transclude.
</sch:assert>
<!-- Embed XRefs in publications should be reverse links. -->
<sch:assert id="EMBED_XREF_NOT_REVERSE"
test="not(@type='embed' and @reverselink='false')"
diagnostics="fragment">Fragment
'<sch:value-of select="ancestor::fragment/@id|ancestor::xref-
fragment/@id"/>'
has an embed cross-reference "<sch:value-of select="."/>"
that is not a reverse link.
Publications only support embeds that are reverse links.
</sch:assert>
</sch:rule>
</sch:pattern>
<sch:diagnostics>
<sch:diagnostic id="fragment">
<sch:value-of select="ancestor-or-self::fragment/@id"/>
</sch:diagnostic>
</sch:diagnostics>
</sch:schema>
Create a schema
To create a new schema requires project manager rights—go to the Template configuration administration page. For each document or media type, there is an option to create a Schematron schema.