How to create a Berlioz index using PSML content
| Skills required | XML |
|---|---|
| Time required (minutes) | 45 |
| Intended audience | Developer |
| Difficulty | Medium |
| Category | Berlioz |
Objective
This tutorial will explain how to create a Berlioz index using PSML content.
Pre-requisites
- Basic understanding of XML
Tutorial
Defining the indexes
The Berlioz configuration file WEB-INF/config/config.xml is where the index (or indexes) are defined, in our example this is the configuration:
<flint>
<watcher max-folders="-1" delay="0" />
<index types="films,bios">
<films name="films" path="/psml/content/films" template="films.xsl"
autosuggests="words,people,movies,usmovies">
<words fields="fulltext" terms="true" />
<people fields="prop_actor,prop_director,prop_producer,prop_writer" />
<movies fields="title,prop_actor,prop_director"
result-fields="image,title,prop_year,prop_genre,prop_country" />
<usmovies fields="title,prop_actor,prop_director"
result-fields="image,title,prop_year,prop_genre,prop_country"
weight="american-level:2" />
</films>
<bios name="bios" path="/psml/content/bios" template="bios.xsl" />
</index>
</flint>
There are two indexes defined: films and bios. For each index, the location of the content to index is defined using the attribute path (relative to the WEB-INF folder) and the name of the XSLT template is referenced in the attribute template.
Implement indexing XSLT
The indexing XSLT is used to transform the PSML content into XML that is parsed by Berlioz to build the index. The XSLT script must be located in the WEB-INF/ixml folder, its file name is defined in the Berlioz configuration file as mentioned above.
The output format is ixml and is defined by a DTD, the ixml version in this example is 5.0, so the output declaration should be the following:
<xsl:output method="xml" indent="no" encoding="utf-8"
doctype-public="-//Flint//DTD::Index Documents 5.0//EN"
doctype-system="https://pageseeder.org/schema/flint/index-documents-5.0.dtd"/>
The Berlioz indexer sends some parameters defining the document indexed, these are:
<!-- file absolute path --> <xsl:param name="_src"/> <!-- file relative path in the index content root folder --> <xsl:param name="_path"/> <!-- file name --> <xsl:param name="_filename"/> <!-- file's last modified timestamp --> <xsl:param name="_lastmodified" />
Each source document produces a single index document using a simple template:
<xsl:template match="document">
<document>
<field name="uriid" tokenize="false">
<xsl:value-of select="/document/documentinfo/uri/@id"/>
</field>
<field name="type" tokenize="false">
<xsl:value-of select="@type"/>
</field>
<field name="title" tokenize="true">
<xsl:value-of select="(.//heading)[1]"/>
</field>
<field name="fulltext" tokenize="true">
<xsl:value-of select="concat(
string-join(section/properties-fragment/property/@value, ' '), ' ',
string-join(section/properties-fragment/property/value, ' '), ' ',
string-join(section/fragment, ' ')
)"/>
</field>
<field name="index" tokenize="false" numeric-type="int">
<xsl:value-of select="replace($_filename, '(film-|\.psml)', '')"/>
</field>
<!-- field used add more weight to american movies -->
<field name="american-level" tokenize="false" numeric-type="int">
<xsl:value-of
select="if (.//property[@name = 'country']/@value = 'USA') then 2 else 0" />
</field>
<!-- use sections -->
<xsl:apply-templates select="section" />
</document>
</xsl:template>
In this template, there are six index fields defined: two metadata fields (uriid and type, non-tokenized), two searchable tokenized fields (title and fulltext) and two numeric fields (index used as an example and american-level that will be used in an autosuggest example).
More fields coming from PSML properties are added using templates matching specific sections:
<!-- Details -->
<xsl:template match="section[@id='details']">
<xsl:for-each select="properties-fragment/property">
<xsl:choose>
<xsl:when test="value">
<xsl:variable name="field" select="@name" />
<xsl:for-each select="value">
<field name="prop_{$field}" tokenize="false"><xsl:value-of select="."/></field>
</xsl:for-each>
</xsl:when>
<xsl:when test="xref">
<xsl:variable name="field" select="@name" />
<xsl:for-each select="xref">
<field name="prop_{$field}" tokenize="false"><xsl:value-of select="."/></field>
</xsl:for-each>
</xsl:when>
<xsl:otherwise>
<field name="prop_{@name}" tokenize="false"><xsl:value-of select="@value"/></field>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</xsl:template>
<!-- About -->
<xsl:template match="section[@id='summary']">
<field name="summary" store="compress"><xsl:value-of select="string(.)" /></field>
</xsl:template>
<!-- Links -->
<xsl:template match="section[@id='image']">
<xsl:if test=".//image">
<field name="image" tokenize="false">/content/films/<xsl:value-of select="(.//image)[1]/@src" /></field>
</xsl:if>
</xsl:template>
<!-- Ignore other sections -->
<xsl:template match="section" />
Each property in the details section adds a non tokenized index field with a dynamic name prop_[name]. The content of the summary section is indexed as a single compressed field called summary and the first image found in the image section will be indexed as a field which value is the path to the image. Other possible sections are ignored.
Indexing the content
Now that the way to index the content has been defined, it is time to access the index management interface. To do so, simply start the jetty server and access the bzindex interface using the path /movies/bzindex.html. For example, if the jetty server is running as localhost using the port 8443, the path is https://localhost:8443/movies/bzindex.html.
The home page lists the indexes available in the server. The first time there should be no indexes in the list (note that if you've been on the main page first –https://localhost:8443/movies – then there might be one or two indexes created, as they are created when needed, but they should be empty).
The definitions page lists all the index definitions available from the config file described in the step 1. In this example, there are two definitions available: films and bios:
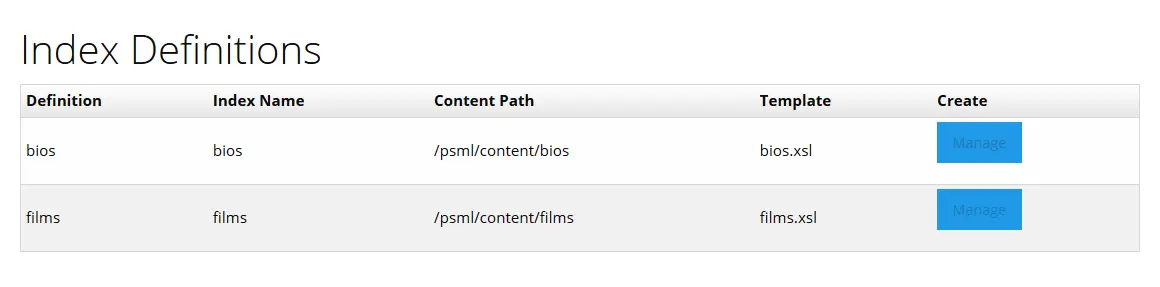
Each definition can be accessed by clicking the manage button and on the new page, the definition is then listed from the configuration file.
The corresponding index can be created using the create button if it does not exist yet. Both indexes should be created from both definitions, the home page (Indexes) should now look like this:
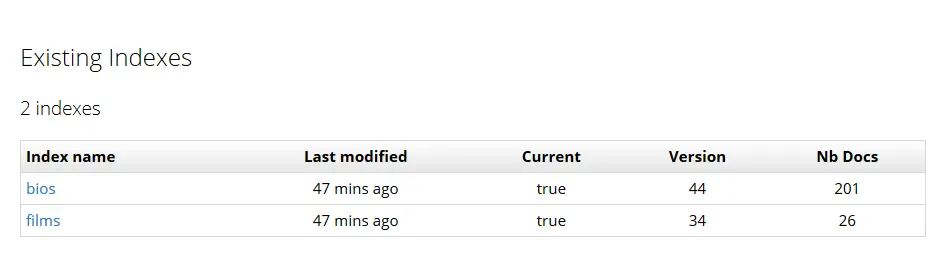
Each index can now be accessed by clicking its name in the list.
When viewing an index in the bzindex interface, the index statistics are listed on the left hand side and some actions are available on the right hand side. The actions are the following:
- Show catalog – list the index's fields at the time they are indexed.
- Show fields – list the index's contents by field. Very useful to make sure the index contains the expected documents and fields. Note that the entire content can be listed so it could be costly for big indexes.
- Translate single file – show the iXML output for a single file, the path to specify is relative to the content root folder of the index (i.e.
/film-21.psml). This is useful for debugging an XSLT template. Also displayed on the result page is the Lucene document that will be added to the index by listing its fields. - Advanced search – a page to run a search on the index by searching a term in a any field specified along with facets.
- Index content – used to index the content from the source folder. Some filters can be applied as to what is indexed:
- from a specified folder (relative to the content root folder), use '/' to index all the content
- only indexed documents modified after a certain date
- only index documents which path matches a regular exception (path relative to the content root folder).
- by default, documents are indexed only if the source has been updated and is different from its resulting document in the index (this allows to index the entire content folder but only update the modified documents). The
Ignore Index Dateoption is available to force a re-index of the same content, for example if the ixml template has been modified. - Clear – remove all content from the index.
- Remove – remove the index from the list of indexes (can be re-created from the definition page).
There is also a basic search available, it accepts a valid Lucene predicate and has a checkbox that can be used to specify that the field searched is non-tokenized (usually a keyword or an ID). An example of a valid search is fulltext:film.
For this example, after indexing the content of the films index, the index page should show the number of documents in the index as 26 and going on the fields page will show the content of the index by selecting a field.
Accessing the app
The main app webapp can now be accessed using the main URL (e.g. https://localhost:8443/movies).
Home/browse
The home page is used to browse the films index by listing all the movies and providing some facets to filter the results. Each search result is presented as the movie poster and title along with an overlay that appears when the mouse hovers on the image. That overlay displays some metadata about the movie (director, year, cast, genre) and each value is a link:
- clicking on a director or a cast member will search the bios index for that name and go straight to the page corresponding if a single result was found or display the results if more than one result matches the name clicked,
- clicking on the year or a genre will reload the browse page with a selected facet.
Search
The search page contains a form which can be used to search any tokenized field of either index.
The results are displayed in the same way as the browse page, with the bios results containing a small extract of the matching field (useful when searching summary) and a link to the full bio page.
Autosuggest
This page has four examples of autosuggest that use the films index, they are defined in the configuration file described in step 1. All autosuggests are triggered when 2 or more characters are typed in each input field. The definitions are:
- Words – using terms in the
fulltextfield, this can be used as a spellchecker as it lists all the words found in all the index content (typeinteras an example). - People – listing all fields corresponding to a person (director, actor, producer, writer), the entire field is returned as opposed to a single tokenized term (try it by typing
joh). - Movies – searching movie titles, directors and actors, the results are displayed using the movie by showing the poster, title, year and country (try it by typing
joh). - Movie with extra weight for USA – same as above but American movies have a higher priority than non American movies (try it by typing
beand compare with the one above).